dots.tts
A 2B-parameter fully continuous, end-to-end autoregressive text-to-speech system.
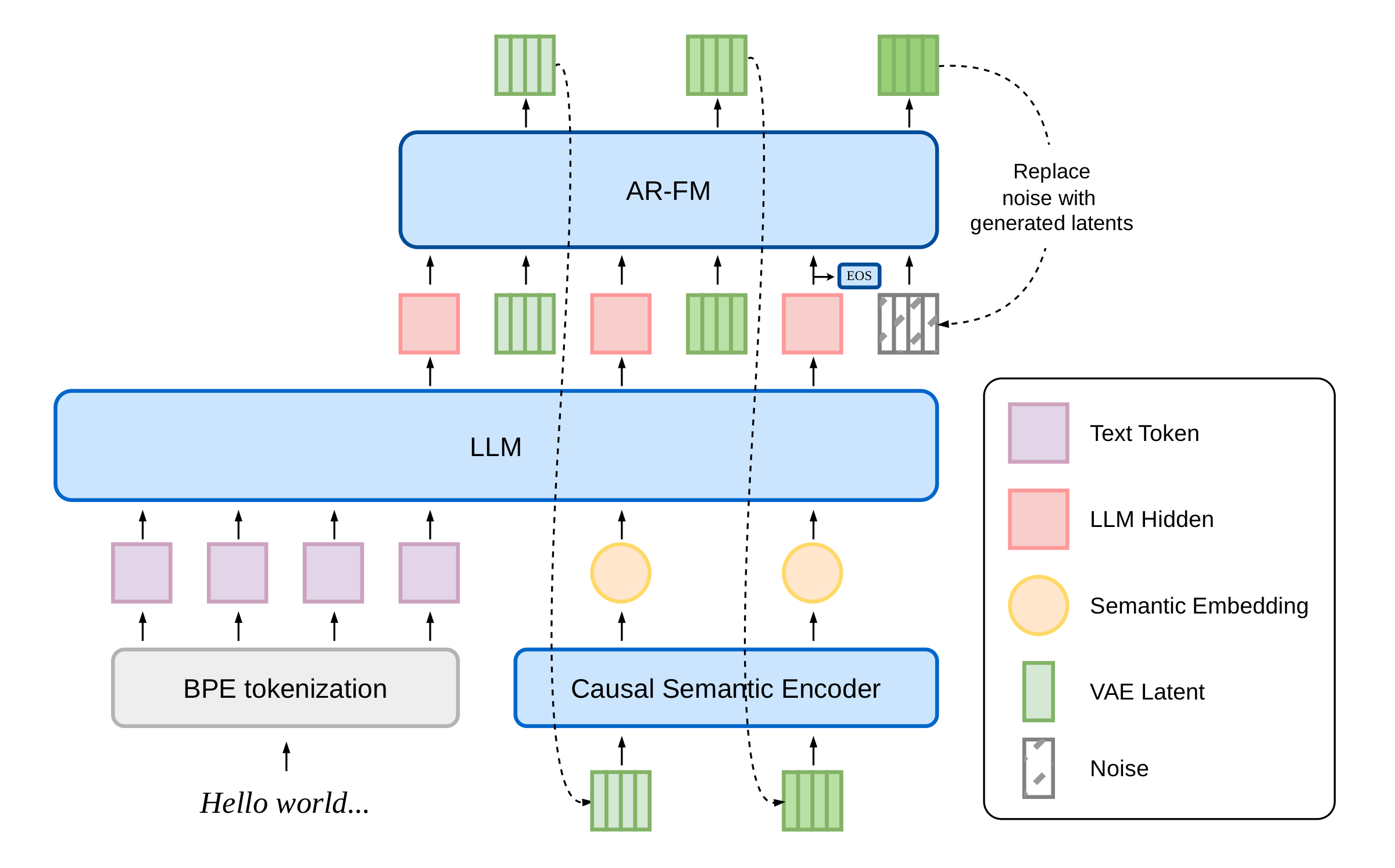
Abstract dots.tts is a 2B-parameter fully continuous, end-to-end autoregressive (AR) text-to-speech system. The backbone pairs a semantic encoder, an LLM, and an autoregressive flow-matching acoustic head over a 48 kHz AudioVAE, with no discrete tokens anywhere in the pipeline.
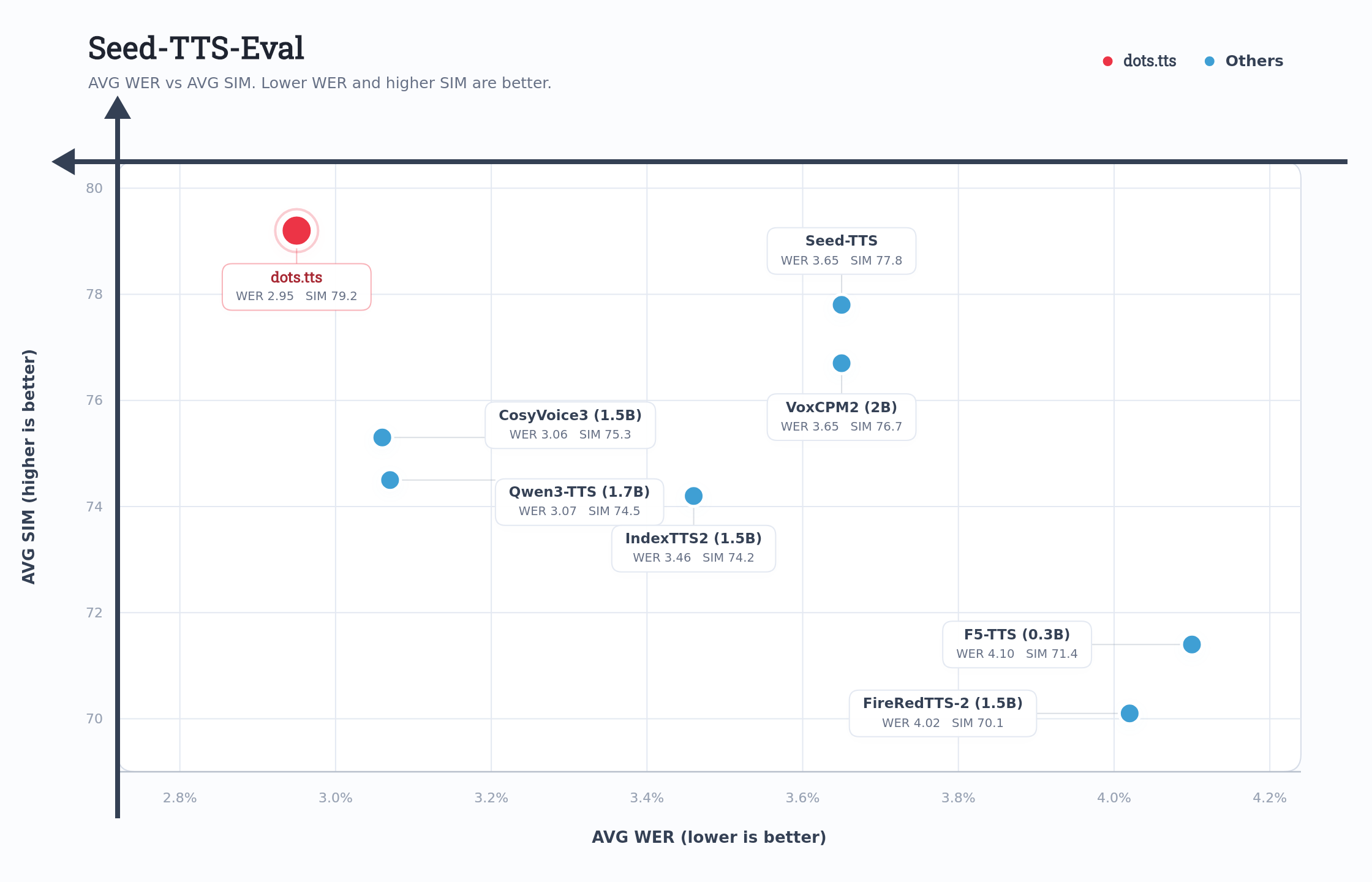
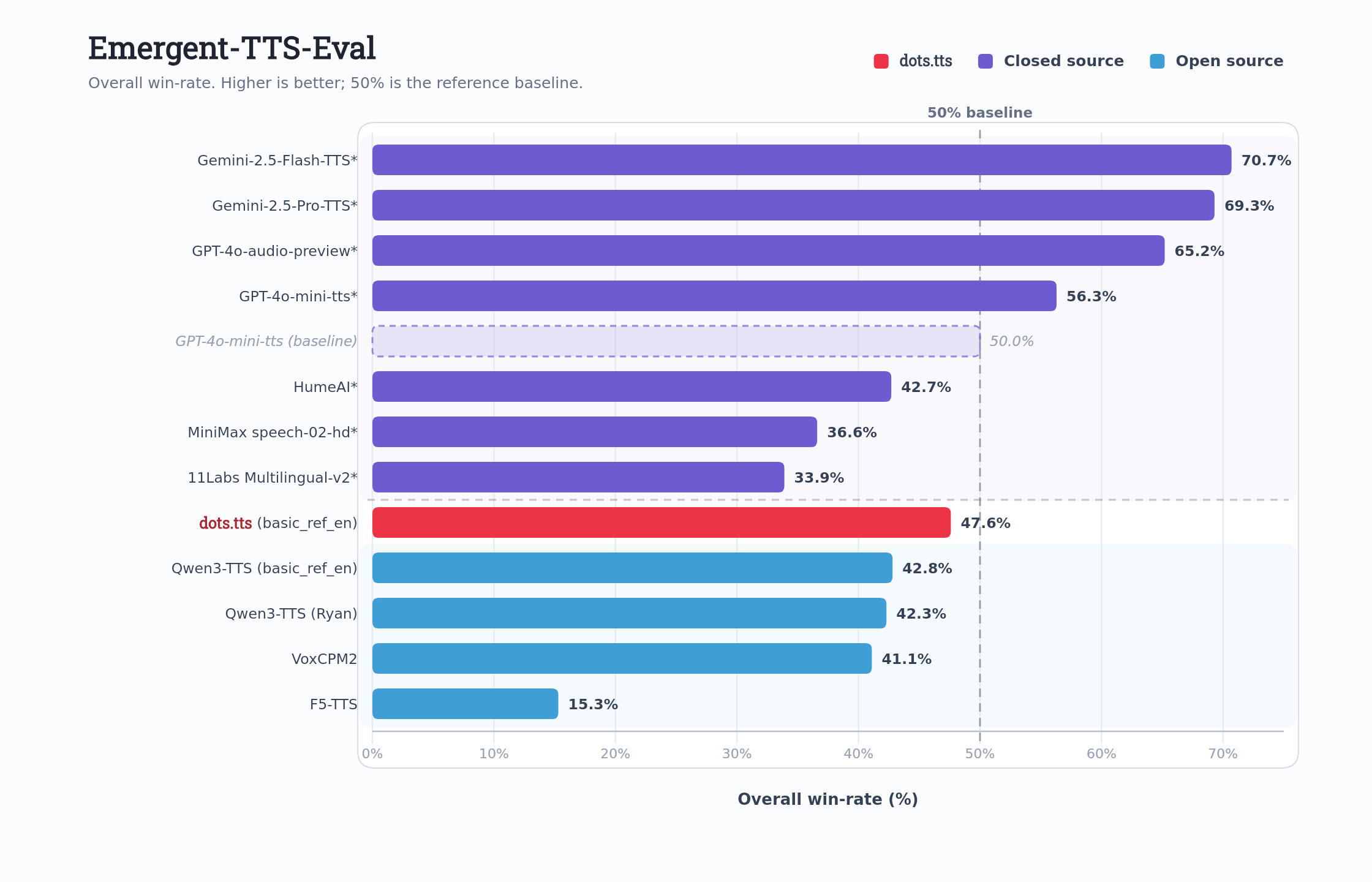
dots.tts achieves the best average performance on Seed-TTS-Eval, with WERs of 0.94% / 1.30% / 6.60% and SIM scores of 81.0 / 77.1 / 79.5 on the zh / en / zh-hard test sets, respectively. It further attains the highest average speaker similarity (83.9) on the 24-language MiniMax multilingual benchmark. Across other benchmarks, dots.tts also consistently demonstrates open-source state-of-the-art performance, exhibiting strong generation stability, voice cloning ability, and emotional expressiveness.
Contents
Overview
Evaluation